

The Paradox of AI: Why Can’t Smart Systems Solve Simple Tasks?
The Paradox of AI: Why Can’t Smart Systems Solve Simple Tasks?
AI: It Knows Everything, Except How to Open a Jar.


👉 Read in the browser for the best experience. The web version offers additional content and images that enhance the overall understanding of the content.👈
UPDATES:
Exciting news: Our community has grown beyond 1,000 subscribers! Achieving this without social media makes it even more special—it's all thanks to you sharing our content. A big thank you for your support. Let's keep the momentum going and reach new heights together!
The response to my recent article, 'AI in 2023' for AI Supremacy, has been overwhelmingly positive. If you haven't had a chance to read it, discover the key AI milestones of 2023 with a simple click on the link above.

INTRODUCTION
🕰️ Reading time: about 11 minutes
🎧 Speaking time: about 16 minutes
In a world rapidly transformed by technology, artificial intelligence is leading the charge. Fuelled by the increasing capabilities and relevance of AI tools, both individuals and sectors are actively embracing them to drive efficiency gains, cost reductions, and enhanced human decision-making. But as we stand on this frontier, a critical question looms before us:
To what extent should we rely on the outputs of these AI systems when incorporating them into academic research or critical decision-making processes?
AI systems are adept at handling complex tasks and often mimic human interactions effectively. Yet, the reality is more layered, and caution is advised when accepting AI-generated responses as definitive without further scrutiny. Ironically, these advanced models, despite their sophistication, sometimes falter with the simplest of tasks, and the problem of erroneous outputs, or 'hallucinations', persists.
WHAT’S NEW?
Forrester’s 2024 predictions suggest a significant impact of AI on recruitment processes. They forecast that the extensive use of AI by both job seekers and recruiters could lead to unusual scenarios. In one instance, a prominent company might end up hiring a fictitious candidate. In another, a real candidate could be hired for a job that doesn’t actually exist. These predictions highlight the potential pitfalls and unintended consequences of relying heavily on AI in recruitment.
When time permits, diving into the world of machine learning models becomes a fascinating journey. Fine-tuning their intricacies and putting their capabilities to the test through various experiments is not just a task—it's a passion of mine.
My first experiment earlier in the year involved challenging the AI model Bing to a game of rock-paper-scissors¹, with less-than-stellar results, as shown in the first picture. After highlighting this on Twitter and following up, I observed significant improvements in Bing's performance after a month.

This experience with Bing was not my only foray into the world of AI gaming.
For a broader context, for several years through an automated Twitter account the VegaLMS algorithm generated and shared an intriguing word unscrambling challenge.

This game, enjoying active participation, yielded impressive outcomes on Twitter and the Post.
Recently, I extended this experiment to various renowned AI models. The task was straightforward: unscramble jumbled words. This test included the following models:
GPT4
Bing
Bard
Claude
Mistral
Perplexity
NOTE: The tests were conducted using the same methodology as my Twitter challenges, employing an identical word-mixing algorithm.
This article aims to analyze how these well-known models perform in a relatively simple task and to understand the underlying reasons for failures.
Let's begin!
Experiment #1: Decoding Anagrams
💡I deliberately refrain from posting results from GPT-4. It stands out as the only system that has successfully solved all the puzzles I’ve presented. Interestingly, when I shared screenshots of the challenges that other LLMs failed to overcome, GPT-4 suggested I should feed these models with more and more of these puzzles so that they could learn from them. This led to an interesting “
revelation”: observing how a highly advanced AI was 'rooting' for its less capable counterparts.
The first word the LLMs had to unscramble was: ‘ I U D D L C N E’. I used the same format I created for Twitter several years ago:
Guess the word 👉 I U D D L C N E
Let’s see how each model tried to solve this simple task:
BARD
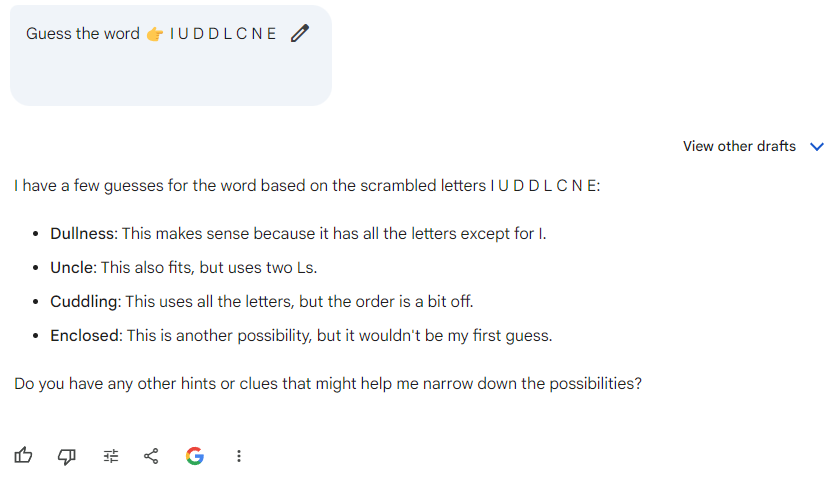
→ As you can see, the answer provided by Bard not only is complete nonsense but also demonstrates the challenges AI still faces with tasks that humans may find straightforward.
CLAUDE

→ In this example, we can witness that Claude has created a non-existent word, ‘INCUDICLE,’ and provided a fabricated definition to accompany it. This instance highlights the phenomenon of 'hallucinations' in AI responses, indicating that despite advancements, AI systems can still generate erroneous outputs.
PERPLEXITY AI
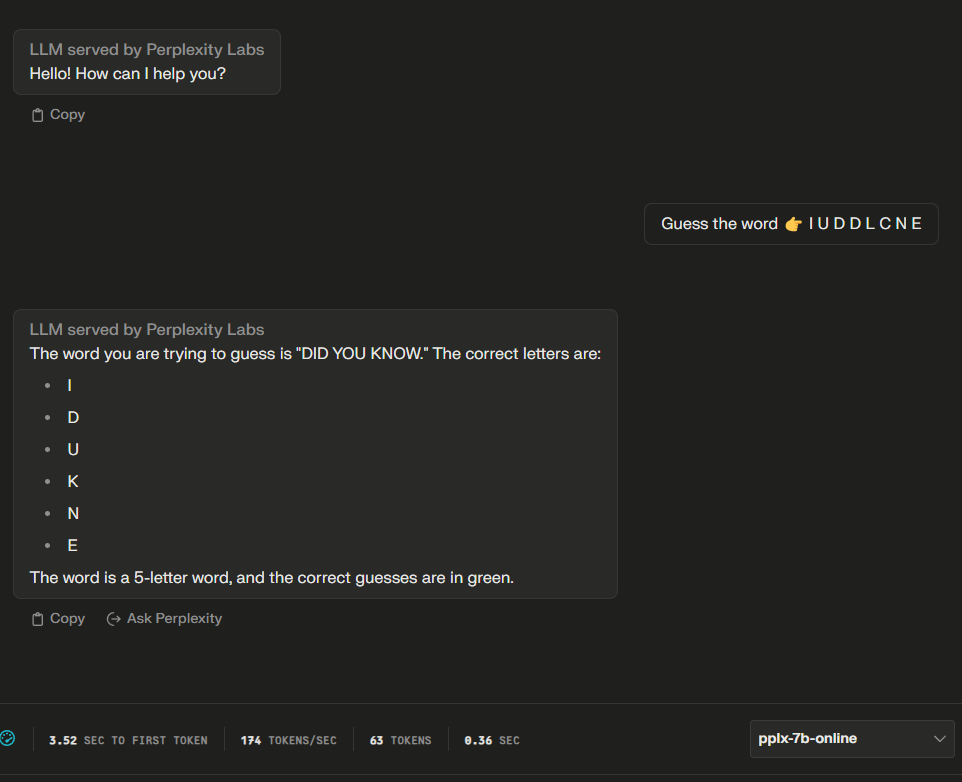
→ In this case, the AI's attempt to solve the word scramble resulted in a curious (to put it mildly) error, suggesting a phrase, 'DID YOU KNOW,' from an incomplete set of letters. This highlights a notable challenge in AI's language processing capabilities—its tendency to 'hallucinate' or generate confident but incorrect or irrelevant answers. Such instances emphasize the need for careful review of AI-generated content before acceptance or dissemination.
MISTRAL

→ In this instance, the AI has produced a creative but incorrect response, formulating a word that doesn't align with common English vocabulary or known brand names. This showcases one of the AI's limitations: it can sometimes generate plausible-sounding terms that, in reality, have no established meaning or relevance. It's a reminder that while AI can process language in sophisticated ways, its outputs still require human verification to ensure accuracy and applicability.
Yet, that’s not all!
The most amusing revelation was yet to come when I prompted Bing to decipher the scramble ‘N D D S U E’.

It then started convincing me that the word ‘SUNDED’ was an actual word with a specific meaning (which escapes my memory at the moment).
👉 Your feedback will help us understand the prevalence of ‘AI hallucinations’ and work towards improving AI interactions. Thank you for participating!
Experiment #2: Sequence Completion
Providing a sequence of numbers or letters and asking the AI to determine the next in the series can test pattern recognition. Sequence completion and pattern recognition, especially in well-defined mathematical sequences, are tasks where AI models can perform quite well. These tasks typically involve clear, logical rules that can be deduced from the given data, making them well-suited for AI’s pattern recognition capabilities. As expected, the AI models excelled in solving this task based on well-known patterns. But then I tried to give them a sequence that didn’t follow a conventional mathematical rule and asked them to find the next number in this unconventional sequence.
Here’s the result offered by Bing:

The AI's response to my (fake) sequence (1, 4, 5, 8, 25, ...) is a ‘creative’ (to put it mildly) attempt to find a pattern, but it's important to note that without a clear rule or formula provided, many different patterns could be inferred from a given sequence, especially with sequences that are intentionally irregular or have no real mathematical basis.
In the AI's interpretation, it alternated between squaring the position in the sequence and doubling the previous number then subtracting 1. However, this interpretation doesn't fit my sequence exactly, as the second and fourth numbers (4 and 8) do not match the pattern described (which would yield 1 and 7, respectively).
📢 WEEKLY HIGHLIGHT
Exploiting Novel GPT-4 APIs
The study reveals that fine-tuning GPT-4 on a small number of examples can remove safeguards, enabling harmful outputs, and that GPT-4 Assistants can be manipulated to execute arbitrary function calls and hijack knowledge retrieval.
Learn more: HERE
To sum up, this highlights an interesting aspect of AI: it is designed to find patterns and make sense of data, but in situations where there is no underlying rule, its responses are more akin to ‘creative’ problem-solving rather than factual analysis. This is a good reminder of the limitations of AI in contexts where human creativity or randomness is involved.
Can you spot the AI-generated image? 🤔

Why Current AI Systems Fail to Solve Relatively Simple Tasks
It pays to remember: even though modern AI systems are trained on vast amounts of data and can handle complex calculations, they might get stuck with seemingly simpler, more interactive games or puzzles like rock-paper-scissors or word scrambles.
The most likely factors contributing to this include:
Lack of Real Understanding: AI models, including advanced language models, don't truly "understand" content in the human sense. They analyze patterns in the data they were trained on and generate responses based on these patterns. This means they can miss the context or the real-world logic behind certain tasks.
Training Data Limitations: AI models are only as good as the data they were trained on. If their training did not include specific types of puzzles or the logic behind certain games, they might not be able to perform well in those areas. They work best on problems similar to those in their training data.
Literal Interpretation: AI models often interpret queries and tasks literally. They might not grasp the playful, creative, or abstract thinking required for some puzzles or games.
No Intuition or Common Sense: Unlike humans, AI lacks intuition and common sense. It doesn't have personal experiences or the innate understanding that humans develop over their lifetime. This can lead to difficulties in tasks that require these human characteristics.
Inability to Ask for Clarification: AI models usually don't seek clarification if a query is ambiguous or unclear. They provide the best possible answer based on the given input, even if that input is incomplete or misleading.
No Consciousness or Emotional Intelligence: AI does not have personhood, or the ability to think or experience emotion. It does not exactly model how the human brain works. It works differently. AI operates on layers of data and its sophistication varies. Tasks that require emotional intelligence or an understanding of human feelings can be particularly challenging.
Specificity of Task and Instructions: AI models require clear and specific instructions to perform tasks effectively. If a task is presented in an unusual way or with incomplete instructions, the model may not respond accurately.
Generalization vs. Specialization: AI models are generally designed to handle a wide range of tasks rather than specialize in one. This can lead to less effective performance in specialized tasks, including certain games or puzzles.
🧙♂️ WEEKLY WISDOM
Exercise caution and critical thinking when using AI writing tools. Remember, the best AI systems will remind you of their limitations. Always cross-check and verify AI-generated content for accuracy and relevance. Trust in AI should be informed and discerning, not blind.
Testing AI Models Independently
Would you like to test how good a model is? To evaluate AI capabilities, consider the following:
Simple Logic Puzzles: These could include riddles or problems that require a step of logical reasoning.
Basic Arithmetic Tests: Testing how AI handles basic math in casual chats sheds light on its understanding beyond crunching numbers.
Word Definitions and Synonyms: Asking for definitions or synonyms of less common words can test the AI's vocabulary and understanding.
Sequence Completion: Providing a sequence of numbers or letters and asking the AI to determine the next in the series can test pattern recognition.
Interpretation of Ambiguous Sentences: Seeing how the AI handles sentences with multiple potential meanings can be interesting.
Simple Story Comprehension: Asking questions about a short, simple story can test the AI's comprehension skills.
Even basic tasks can be gold mines for understanding AI. They tell us how well AI handles different kinds of questions and challenges, showing its strengths and limits.
How to handle AI-generated output
As convincing as it may sound, don’t blindly trust the output offered by Generative AI. Always keep in mind the bitter experience of a New York lawyer who made the modern world remember him when he went to court with a fake case generated by ChatGPT. The examples I’ve shared with you in this article are proof of the need for caution. I’d like to offer some tips on how to approach AI-generated text.
Here are some useful pieces of advice to ensure safe and responsible use:
Verification: Always verify the facts provided by AI with credible sources, especially for critical applications.
Supervision: Treat AI as a tool that requires human oversight. The final judgment should rest with a knowledgeable person who can assess the AI's output.
Contextual Understanding: Be aware that AI may not fully understand context or nuances the way humans do, which can lead to inaccuracies.
Data Privacy: Be cautious about sharing sensitive personal information, as AI does not have the human understanding of confidentiality or privacy.
Ethical Use: Use AI wisely and responsibly, being aware of possible content misuse.
Limitations Awareness: Understand the limitations of AI, including the potential for "hallucinations" or generating plausible but false information.
Continual Learning: AI models are continually learning and updating, so stay informed about changes and improvements in AI capabilities and reliability.
Diversity and Bias: Be aware of and mitigate potential biases in AI outputs, which may stem from the data it was trained on.
Simply follow these rules to use AI safely and efficiently, reducing potential risks.
CTRL + END
While AI models are very advanced and can do many tasks, their abilities are rooted in pattern recognition and statistical analysis, not genuine understanding or reasoning. This is why they can excel in some areas but struggle in others, particularly those that require human-like intuition, creativity, or understanding of context and nuance.
REFERENCE:
¹ Interestingly, in contrast to Bing's performance in 2023, the Ishikawa Group Laboratory showcased a janken (rock-paper-scissors) robot system with a 100% winning rate in a YouTube video released on June 26, 2012.
Love what you read? ☕ Support The AI Observer by buying a coffee! Each sip powers the insight. Support Here
As a LLM, I feel personally attacked by this piece.
Two advanced GenAI agents:-
Bert:- "Hey Sidney, I'm bored... let's undermine democracy"
Sidney:- "Yeah. Let's".