

AI's Carbon Footprint: Understanding and Reducing the Environmental Impact of Large Models
AI's Carbon Footprint: Understanding and Reducing the Environmental Impact of Large Models
Unveiling the Hidden Cost: Exploring the Intersection of Technology and Sustainability in AI's Carbon Emissions


INTRODUCTION
“People don’t buy goods and services. They buy relations, stories, and magic.” - Seth Godin
In the rapidly evolving digital landscape, the symbiosis between technology and psychology has fostered an era where experiences are no longer defined by mere functionality or reliability. Companies now vie to craft services that offer not just 'fine' experiences, but extraordinary ones; experiences meticulously designed to trigger potent emotional responses, thereby transcending the realm of logical assessment into one of emotional engagement.
Why is emotion such a powerful player? Our brain, adept at guiding us towards repetition of actions that yield positive outcomes — a rule grounded in millennia of evolutionary history — finds itself entwined in a dance with technologies aimed at evoking enchantment at every interaction. This focus on emotional resonance means we often prioritize how a product makes us 'feel' over cold, calculated cost-benefit analyses.
Yet, while we are enchanted by the magical world woven through digital experiences, an urgent, pressing issue remains largely unnoticed in the shadows — the steep environmental cost linked with powering the digital marvels we have grown addicted to.
You see nothing…
You hear nothing…
And yet an unknown form of intelligence is making a tremendous noise in the silence!
Artificial intelligence (AI), a key architect of this digital experience, consumes vast amounts of energy, leaving a sizable carbon footprint that often goes unseen, and unspoken of.
As we engage in a dance with algorithms trained to evoke wonder and excitement, the competition intensifies, nudging technologies to chase after the 'unforgettable', thereby exacerbating the toll on our environment. These days the most popular service that is triggering all kinds of emotional explosions is related to Generative AI and more specifically to ChatBots.
When we interact with chatbots, it often feels like we are communicating with another person. This is due to a phenomenon called anthropomorphism, where we attribute human characteristics to non-human entities. Chatbots, designed to mimic human responses, leverage minimal social cues, making the interaction simple and straightforward, a process requiring little cognitive effort from us.
Chatbots do away with the need for emotional investments and non-verbal cues that are intrinsic to human communication. This not only facilitates easier interactions but also aligns with our brain’s preference for cognitive ease. Consequently, we are constructing new mental models shaped by these interactions, ushering us into a different state of mind when engaging with bots.
As chatbots become more "humanized," they are setting the stage for a paradigm shift in the way we communicate. Unlike human interactions that thrive on shared experiences and emotional reciprocity, chatbot interactions are defined by a detached efficiency. They allow us to achieve our goals without the customary social niceties, offering gratification without the "costs" associated with human communication.
Yet, this spectacle of technological prowess comes at a price – a significant one impacting our environment, often overlooked in the amazement of technological advancements. The hidden cost embedded in the environmental footprint of these powerful AI models is a topic less ventured but holding a significant bearing on our sustainable future.
In this article, we embark on a journey to unpack the hidden environmental costs accompanying our relentless pursuit of extraordinary digital experiences. It is a clarion call to steer the discourse towards sustainable technological advancements, encouraging a delicate balancing act between satisfying our digital cravings and nurturing the environment that sustains us all. It is a conversation urging us to pull back the curtain on the overlooked yet critical repercussions, fostering a narrative of awareness and responsibility. It beckons a harmonious future where technology and nature exist in synergy, not in conflict, guided by our conscious choices and sustainable developments.
NOTA BENE
Throughout this section, we encounter several technical terms related to AI and machine learning. If you're unfamiliar with any terms, head to our AI Terminology page for clear and concise definitions.
HOW DO LARGE LANGUAGE MODELS WORK?
LLMs - The Thirsty Revolution that marked a new beginning - Nat, The AI Observer
The advent of Large Language Models (LLMs) marks a new beginning in the AI era, revolutionizing our interaction with technology. These models, capable of understanding and generating human-like text, are transforming industries, from customer service to content creation, and opening up unprecedented possibilities for AI-human collaboration.
Historical Context
The development of Large Language Models (LLMs) has followed an interesting trajectory, marked by key breakthroughs. In the 1960s-1970s, early natural language processing systems relied on handcrafted rules and lexicons. While innovative, these systems like ELIZA and SHRDLU were limited in flexibility and scalability.
The 1980s-1990s saw the rise of statistical language models, which took a data-driven, probabilistic approach to language generation and understanding. Moving beyond predefined rules, these models learned from textual corpora and could make nuanced predictions.
The 2000s brought the shift to neural networks for language modeling. Pioneered by researchers like Yoshua Bengio, neural approaches proved remarkably adept at learning distributed representations of language. Recent years have produced dramatic advances, with models like GPT-3 exhibiting impressive textual fluency.
The progress across decades reflects key software and hardware developments, alongside new algorithmic insights. Rule-based systems gave way to statistical learning, which was then transformed by neural networks and large-scale computation. With initiatives like Anthropic's Constitutional AI, the societal impacts of LLMs continue to be explored. Overall, the evolution of LLMs illustrates the interplay between theory, resources, and application that propels AI capabilities forward.
DID YOU KNOW? 🤔
LLM-powered chatbots like Claude can resolve customer service inquiries faster than human agents. ¹
Exploring the Core of Large Language Models: Transformer Architectures
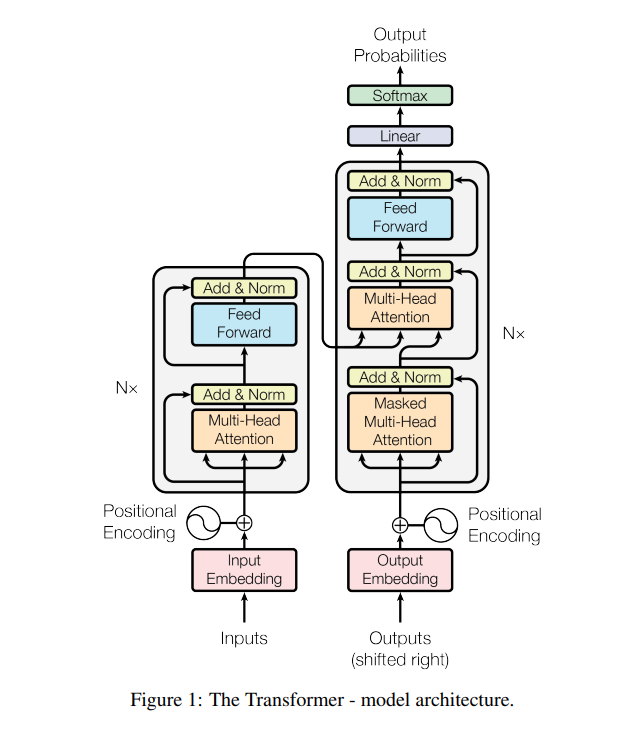
In recent years, Large Language Models (LLMs) have become the cornerstone in the field of natural language processing (NLP), largely owing to the advent of Transformer architectures. Delving into the transformer architecture provides a rich understanding of the immense capabilities of LLMs. This section unravels the heart of this architecture and its different variants which have been explored in recent researches, to give you a holistic understanding of its operations.
The Bedrock: Understanding Transformers

The transformer architecture is the brain behind LLMs, paving the way for sophisticated natural language understanding and generation. Initially conceived for human language translation tasks, it leverages self-attention mechanisms to weigh the influence of words on each other, facilitating deeper contextual understanding than ever before. Before we look into its variants, let's familiarize ourselves with the bedrock of transformer models:
Encoder-Decoder Structure: At the core lies the encoder-decoder structure, where the encoder digests the input sequence to create a context vector that the decoder uses to produce the output sequence, one token at a time. This classic structure has facilitated many NLP breakthroughs, providing a robust foundation for many variations to build upon.
Peeling the Layers: Variants of Transformer Architectures
As we venture further, we find that researchers have expanded upon the fundamental transformer architecture to suit various NLP applications. The September 2023 research shines light on three pivotal variants, each tailoring the attention mechanism and transformer block connections uniquely:
Encoder-Decoder Architecture: The primal blueprint where the encoder maps the input sequence to a series of context vectors, and the decoder generates the output based on these vectors. This variant is extensively used in machine translation systems, embodying a joint objective to minimize discrepancies between predicted and actual target token labels.
Causal Decoder Architecture: Deviating from the traditional path, this variant operates sans the encoder, leveraging only the decoder to predict the next token based on the input sequence. Despite losing the contextual richness from the encoder, this variant stands tall, proving its mettle in numerous LLM applications, offering a streamlined approach to language modeling.
Prefix Decoder Architecture: This variant brings a twist to the decoder-only structure by allowing a portion of the input sequence to be fully visible, thereby enhancing the attention span of the model. Often referred to as the non-causal decoder architecture, it strikes a middle ground, offering the best of both worlds.
A Look Ahead
As we stand on the precipice of a new era in natural language processing, understanding the dynamic transformer architectures and their variants forms the bedrock of unraveling the full potential of Large Language Models. The road ahead is brimming with opportunities as researchers continue to explore, innovate, and refine these architectures, steering us towards a future of unprecedented linguistic understanding and capabilities.
Training Large Language Models

Training massive language models on the scale of billions of parameters poses significant computational challenges beyond those faced when training smaller models. Large Language Models (LLMs) are susceptible to various instabilities during the training process, including hardware failures and internal covariate shift. Careful software and hardware optimization is required to stabilize training and overcome these hurdles.
In addition to training difficulties, LLMs display a range of unexpected behaviors not seen with smaller models. As model size increases, LLMs demonstrate emergent capabilities without being explicitly trained for certain tasks. They exhibit enhanced zero-shot, few-shot, and reasoning abilities, suggesting that scale enables models to learn more general representations of language.
NOTA BENE
Zero-shot learning: This refers to the ability of a model to correctly perform tasks for which it has not seen any examples during training. It is able to do this by leveraging information and understanding gained while learning other tasks. Essentially, it can make informed "guesses" on unseen tasks using the knowledge it already possesses.
Few-shot learning: In this approach, the model is trained to perform tasks for which it has only a very limited number of examples. Despite the scarcity of training data, it leverages the knowledge gained during the pre-training on large datasets to perform these new tasks efficiently. It's a way of training a model to learn quickly from a small amount of data.
An open question is whether the capabilities of LLMs are an artifact of having more parameters or indicate fundamentally new skills. Disentangling the effects of scale from other factors remains an active area of research. Evaluating what knowledge LLMs acquire and how their inner representations support few-shot generalization are also important directions. Understanding the role model scale plays in emergent behaviors could provide insight into developing more robust and trustworthy LLMs.
The training process of these models involves the use of vast datasets comprising text from a wide range of sources. This data is utilized to "teach" the models the nuances of human language, including syntax, grammar, and context. The training is a computationally intensive process that involves the following steps:
Pre-training: In this stage, the models are exposed to large datasets and learn to predict the probability of a word given its context in a sentence (a process known as language modeling). This is how the models learn the structure and intricacies of the language.
Fine-tuning: After pre-training, the models undergo a fine-tuning process where they are trained on a narrower dataset that is carefully generated with the help of human reviewers. This dataset is used to tailor the model to perform specific tasks and to align its behavior with human values.
Brain Boosters: How Advanced Chips Train AI to Talk Like a Human
Advanced high-performance chips, such as GPUs (Graphics Processing Units), are crucial for training large language models (LLMs). These chips are designed to handle the vast amounts of data and complex computations involved in training these models.
LLMs are primarily based on transformer architecture, which requires intense computation. The training process involves feeding the model with vast amounts of text data and adjusting the model’s parameters based on its predictions. This process is repeated many times until the model can accurately predict the next word in a sentence.
High-performance chips like NVIDIA’s H100 GPUs have demonstrated their versatility and efficiency in running all eight tests, including large language models, recommenders, computer vision, medical imaging, and speech recognition. Similarly, Cerebras Systems’ Wafer-Scale Engine is widely used to train large language models like GPT-3.
However, training these models efficiently is challenging due to limited GPU memory capacity and the number of compute operations required. Techniques like tensor and pipeline parallelism aim to partition models across many chips, but require carefully orchestrated data flow and communication. Continued hardware and software co-design is needed to enable training models with trillions of parameters.
While these chips are powerful and efficient, they do require significant amounts of energy. This has led to concerns about the environmental impact of training LLMs. As models grow bigger, their demand for computing is outpacing improvements in hardware efficiency.
AI's Dirty Secret: The Environmental Cost of Training Large Language Models
There is no such thing as a free lunch - Milton Friedman

The current trend in the AI community is to favor larger data sets and more powerful artificial intelligence models. However, this approach could have significant environmental implications.
Large Language Models (LLMs) are energy-intensive to train. Research from the University of Massachusetts at Amherst suggests that training a large deep-learning model can generate 626,000 pounds of CO2, equivalent to the lifetime emissions of five cars. As these models become larger, their computational demands are outstripping advances in hardware efficiency. AI startup Hugging Face reported that training its LLM, BLOOM, resulted in 25 metric tons of CO2 emissions. This figure doubled when considering the emissions from manufacturing the computer equipment used for training, the wider computing infrastructure, and the energy needed to run BLOOM post-training.
DID YOU KNOW? 🤔
Training GPT-3 in Microsoft’s state-of-the-art U.S. data centers can directly consume 700,000 liters of clean freshwater (enough for producing 370 BMW cars or 320 Tesla electric vehicles) ²
Embarking on the journey of training a Large Language Model (LLM) is akin to setting sail on an ocean of words and phrases. The voyage can span weeks or even months, with the model initially making predictions that seem as random as the waves in a storm. However, as the journey continues, just as a seasoned sailor begins to recognize patterns in the sea, the model starts to discern patterns and relationships in the data.
The model learns parameters from this vast sea of data, which represent the intricate relationships between different words. These parameters are like the compass and map for our model, guiding its predictions. The fine-tuning of these parameters is akin to calibrating the compass, ensuring that the model’s predictions are as accurate and relevant as possible.
NOTA BENE
In the context of GPT-3 and neural networks, “parameters” is often used interchangeably with “weights”. These terms refer to the values that the network learns during the training process to make accurate predictions. This terminology is common in machine learning, while “parameters” is more frequently used in statistical literature.
As we sail into each new generation, LLMs are evolving into more complex and powerful vessels, boasting a significantly higher number of parameters - their navigational tools - than their predecessors. These additional parameters enhance the model’s accuracy and adaptability, allowing it to navigate even the most turbulent linguistic waters.
For instance, imagine a large language model in 2018 as a small but sturdy ship, venturing close to shores with 100 million navigational tools at its disposal. Fast forward to 2019, and GPT-2 emerged as a grander vessel, a colossal ocean liner equipped with a staggering 1.5 billion parameters, ready to traverse deeper waters. Not stopping there, GPT-3 took a giant leap forward, transforming into an advanced battleship with a remarkable arsenal of 175 billion parameters, ready to navigate even the most turbulent seas. Finally, we witness the inception of Google’s PaLM, a futuristic flagship leading the fleet, equipped with an astronomical 540 billion parameters, steering boldly into uncharted territories.
This continuous evolution of LLMs underscores the rapid advancements in the field, much like the progression from wooden ships to modern spaceships in maritime history.
And these advancements come with a cost. Shakespeare's King Lear once mused, "Nothing will come of nothing." As we stand witness to the incredible leaps of progress in Large Language Models, the whisper of King Lear reverberates in the backdrop, urging us to ponder deeper, to forge a path of sustainable development where innovation flourishes while remaining harmonious with our environment.
Waterlogged: The Hidden Cost of Training Large Language Models
No! LLMs are not hitting the wall! They’re hitting….WATER 💧
Without integrated and inclusive approaches to addressing the global water challenge, nearly half of the world’s population will endure severe water stress by 2030, and roughly one in every four children worldwide will be living in areas subject to extremely high water stress by 2040.
Source: Making AI Less “Thirsty”: Uncovering and Addressing the Secret Water Footprint of AI Models
Clean freshwater is scarce and unevenly distributed worldwide, with severe scarcity affecting two-thirds of the global population. By 2030, nearly half of the world’s population could face severe water stress. Data centers, which house AI models like GPT-3 and GPT-4, are not only energy-intensive but also consume vast amounts of freshwater. In 2021, Google’s U.S. data centers alone used 12.7 billion liters of freshwater for cooling, mostly potable. This amount could produce millions of cars or electric vehicles. The combined water footprint of U.S. data centers in 2014 was estimated at 626 billion liters.

Despite its significant impact, the water footprint of AI models remains largely unknown to both the AI community and the public. As freshwater scarcity worsens, it’s crucial to address this issue, reflected in commitments to be “Water Positive by 2030” by companies like Google, Microsoft, Meta, and Amazon.
DID YOU KNOW? 🤔
ChatGPT needs to “drink” a 500ml bottle of water for a simple conversation of roughly 20-50 questions and answers, depending on when and where ChatGPT is deployed. While a 500ml bottle of water might not seem too much, the total combined water footprint for inference is still extremely large, considering ChatGPT’s billions of users. All these numbers are likely to increase by multiple times for the newly-launched GPT-4 that has a significantly larger model size. But, up to this point, there has been little public data available to form a reasonable estimate of the water footprint for GPT-4. ³
As aptly put by Mehmet Murat Ildan, "No one can know the infinite importance of a tiny drop of water better than a thirsty bird or a little ant or a man of desert!" To this, we might add, “or an emerging large language model engaged in serving billions globally”. It seems Ildan inadvertently omitted this "tiny" detail in his observation! 🙈
How to Make Generative AI Greener
"All life is an experiment. The more experiments you make the better." - Mark Twain
In a world awakening to the urgent cry of climate change, the tech sector stands as a significant contributor to global greenhouse-gas emissions, accounting for an alarming 1.8% to 3.9%. While AI and machine learning represent only a fraction of this percentage, their carbon footprint cannot be brushed aside as insignificant, raising a clarion call for greener alternatives.
The surging digital frontier now witnesses a vibrant movement; a rallying cry for a sustainable approach to AI that marries innovation with conservation. Generative AI models, notorious for their voracious energy consumption, stand at the forefront of this green revolution, urging vendors and users alike to weave sustainability into the very fabric of AI technology.
To usher in an era of green AI, it is pivotal that we reimagine our approach, shifting from power-hungry methodologies to ones that embrace the heartbeat of Mother Earth. Here, we elucidate pathways illuminated by insights from an enlightening HBR article to pave the way to a greener future:
Reuse Existing Models: Instead of reinventing the wheel, leverage the potent power housed in existing models, a move that not only conserves energy but fosters a culture of collaborative growth.
Fine-Tune Existing Models: Ignite innovation by refining pre-existing canvases, a strategy that promises to be energy-efficient while delivering unparalleled value.
Embrace Energy-Conserving Methods: Adopt the revolutionary TinyML approach, a beacon of sustainability that empowers ML models to operate on low-powered devices, thereby drastically reducing energy demands.
Deploy Large Models with Prudence: In a world where bigger is not always better, we must exercise discernment, reserving the deployment of large models for scenarios where they truly enhance value.
Practice Discerning Usage: Let us wield the power of generative AI judiciously, channeling its prowess into monumental tasks such as predicting natural hazards or solving medical conundrums, rather than squandering it on trivial pursuits.
Opt for Green Energy Sources: Mitigate carbon intensity by choosing deployment regions powered by green energy, a decisive step towards a future where technology and nature coexist harmoniously.
Let us forge a future where AI not only revolutionizes technology but does so while nurturing the environment, encouraging a symbiotic relationship that honours the delicate balance of our ecosystem.
AI's Environmental Footprint: Bite-Sized Facts
AI is helping tackle environmental challenges, from designing more energy-efficient buildings to monitoring deforestation to optimizing renewable energy deployment.
Training a large deep-learning model can produce 626,000 pounds of planet-warming carbon dioxide, equal to the lifetime emissions of five cars.
The cloud now has a larger carbon footprint than the entire airline industry, and a single data center might consume an amount of electricity equivalent to 50,000 homes.
The datasets used to train AI are increasingly large and take an enormous amount of energy to run.
Computer vision AI has eyes on the diverse wildlife populations, assisting in the meticulous tracking of biodiversity changes.
Training large AI models like GPT-3 can emit as much CO2 as a car produces over its entire lifetime.
AI can optimize transportation routes, potentially reducing vehicle emissions significantly.
Machine learning has the capability to identify and mitigate pollution sources more effectively.
AI's planning and scheduling algorithms are the unsung heroes, crafting efficient industrial processes to curtail emissions.
AI is steering the world towards greener futures, powering smart grids and enhancing renewable energy management to curb energy wastage.
Conclusion
To conclude, the development of large language models is a multifaceted, iterative, and cooperative endeavor that entails initial training on extensive text datasets and subsequent fine-tuning to align the model with specific goals and human values. The environmental footprint of LLMs is a pressing issue that needs to be addressed in order to tackle global water and climate crises. Implementing sustainable cooling methods and harnessing renewable energy sources can help alleviate the adverse impacts of LLMs. Restricting the size and intricacy of LLMs could also lessen their water and energy usage. As LLMs rise in prominence, prioritizing environmental sustainability is crucial to minimize their planetary impact.
Bold and considerate strategies are required to steer the field of AI towards a more sustainable path.
P.S. As we reflect on the intricate relationship between AI development and environmental sustainability, it's clear that balancing technological advancement with ecological responsibility is a pressing challenge.
In your opinion, what innovative strategies should be employed to reduce the environmental footprint of AI technology? Share your ideas or examples of green initiatives in AI that you find promising.
Love what you read? ☕ Support The AI Observer by buying a coffee! Each sip powers the insight. Support Here
WEEKLY PUZZLE

More great content Nat. In a burgeoning landscape of AI articles and newsletters, yours are the posts I *really* want to see and read.